Deep Unsupervised Speech Representation Learning
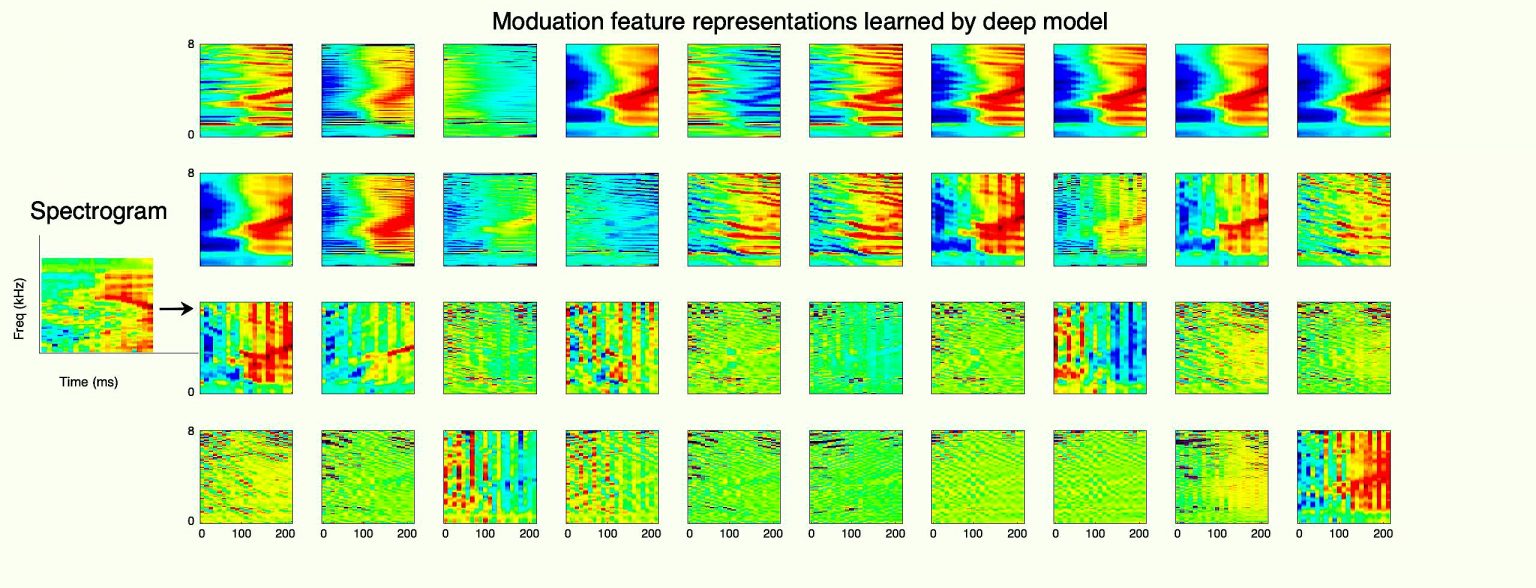
The performance of speech systems is degraded in the presence of noise. The principle of modulation filtering attempts to remove the spectro-temporal modulations that are susceptible to noise. While traditional approaches use modulation filters that are hand-crafted, we propose a novel method for modulation filter learning using deep variational models. Specifically, we pose the filter learning problem in an unsupervised generative modeling framework where the convolutional filters capture the modulations that are shown to improve speech recognition performance significantly.
References
Purvi Agrawal, Sriram Ganapathy:
Modulation Filter Learning Using Deep Variational Networks for Robust Speech Recognition. IEEE J. Sel. Top. Signal Process. 13(2): 244-253 (2019)
Website: http://www.leap.ee.iisc.ac.in/sriram/
Faculty: Sriram Ganapathy, EE